
🔁 AI w pętli własnych treści: model collapse
Niecodzienne porady do najpopularniejszych narzędzi AI.


🔉Wolisz wersję audio? Nie możesz przeczytać teraz maila?
Przesłuchaj tutaj
Możesz nas słuchać także na Apple Podcast i Spotify.
🎯 W DZISIEJSZYM WYDANIU
🎓 AI od zera do zrozumienia: AI w pętli własnych treści: model collapse
🛠 AI w praktyce: Niecodzienne porady do najpopularniejszych narzędzi AI.
🥡 AI na Wynos:
Nano Banana to najnowszy i prawdopodobnie najlepszy model do generowania obrazów, dostępny za darmo na X po oznaczeniu w poście lub komentarzu z promptem.
Oficjalny poradnik Google wyjaśnia, jak promptować Nano Banana.
Jeden z inżynierów ukradł kod od xAI Elona Muska, a następnie dołączył do OpenAI.
ElevenLabs wprowadziło nową wersję modelu do generowania efektów dźwiękowych.
PKO wypuściło nowy open-source model reprezentacji tekstu o nazwie Polish Roberta 8K.
Norton, znany z antywirusa, pracuje nad nową przeglądarką napędzaną AI.
OpenAI opublikowało nowy poradnik dotyczący promptowania agentów głosowych.
Warp Code to nowe narzędzie do vibe kodowania i pair programmingu.
Nowość w OpenRouter to nowe modele do testowania, które na razie są dostępne za darmo z 2 milionami tokenów kontekstu.
📚 Rekomendowana Biblioteka:
What is AI Model Collapse? (in about a minute) [video]
Scientists warn of AI collapse [video]

Habsburgowie i cyfrowa degeneracja
Widziałeś(-aś) portrety Habsburgów? Te twarze z mocno wysuniętą żuchwą, szczególnie u Karola II Habsburga. Na obrazach wygląda, jakby całe życie się z kimś bił: żuchwa tak wysunięta, że utrudniała żucie, niewyraźnie mówił i ciągłe się ślinił. Skąd to się wzięło? Przez pokolenia w hiszpańskiej linii rodu zawierano małżeństwa w bliskiej rodzinie, kuzyn z kuzynką, wuj z siostrzenicą, żeby nie rozpraszać władzy i majątków. Mówiono o czystości krwi, ale to przede wszystkim była kalkulacja dynastyczna. Tylko, że kumulacja wspólnych przodków zwiększała ryzyko ujawniania się niekorzystnych cech i chorób. U Karola II ten efekt był skrajny.
.")
Ostatecznie hiszpańska linia dynastii wygasła. Karol II był tak schorowany, że zmarł bezpotomnie.
AI może mieć podobny problem.
Pierwsze duże modele uczyły się głównie na ludzkich danych: tekstach i obrazach tworzonych przez nas. Ale kolejne fale coraz częściej karmione są wytworami poprzedników. Z czasem w miksie danych zaczyna może przeważać to, co wygenerowały same modele.
Jaki jest tego efekt? System zaczyna uczyć się na sobie samym. Jak u Habsburgów, krąg się zamyka i dystrybucja danych ubożeje: znikają rzadkie, ale ważne przypadki np. rzadkie choroby w diagnostyce, niszowe dialekty, nietypowe ujęcia i oświetlenie na zdjęciach), a model robi się coraz bardziej przewidywalny i ślepy na wyjątki. Jeśli nie dolewamy świeżej ludzkiej treści i nie filtrujemy syntetycznych danych (czyli tych wygenerowanych przez AI), każde pokolenie jest odrobinę gorsze od poprzedniego.
Wprowadzenie do Model Collapse
AI coraz częściej uczy się na danych, które samo wytworzyło. W literaturze nazywa się to model collapse (mowią nawet “Habsburg AI”): degeneracyjny proces, w którym syntetyczne treści zanieczyszczają trening następnych generacji i prowadzą do stopniowej utraty kontaktu z rzeczywistym obrazem świata.
Widać to nawet na prostych przykładach. W jednym z eksperymentów z małym modelem językowym (OPT-125M) treść o architekturze po kilku rundach uczenia na sobie dryfowała w stronę absurdalnych wyliczanek o zającach z różnymi ogonami, to typowy obraz późnego etapu załamania (czyli po wielu rundach uczenia na własnych wyjściach model zaczyna mieszać tematy i produkować bezsensowny tekst). Nie chodzi jednak wyłącznie o spektakularne wpadki, częściej pojawia się coś bardziej podstępnego: uśrednianie (np. zamiast podać konkretne fakty i liczby, model pisze ogólnikami: "wysoka jakość", "innowacyjne", unika szczegółów i rzadkich terminów).

Kolejne generacje stają się coraz bardziej przewidywalne i podobne do siebie, a różnorodność słów, składni i znaczeń systematycznie maleje, co pokazano w badaniach nad treningiem na tekście syntetycznym.
To nie jest nieuchronny los modeli. Badania wskazują, że da się wyhamować ten mechanizm, jeśli nie zastępujemy ludzkich danych syntetycznymi, lecz je akumulujemy i dbamy o proporcje oraz kurację zbiorów. W takim ustawieniu jakość na nowych, niewidzianych wcześniej przykładach (tzw. błąd testowy) przestaje spadać z generacji modelu na kolejną generację, a degradacja wyraźnie słabnie. Innymi słowy: świeże, dobrze opisane treści od ludzi muszą pozostać stałym elementem dla uczenia kolejnych modeli.
Jak firmy tworzące modele sobie z tym radzą?
Badacze sprawdzili to na realnych modelach i w praktycznych ustawieniach treningu. Widać degradację w tekście i w obrazach, zwłaszcza gdy kolejne generacje uczy się głównie na danych syntetycznych pochodzących od poprzednich modeli.
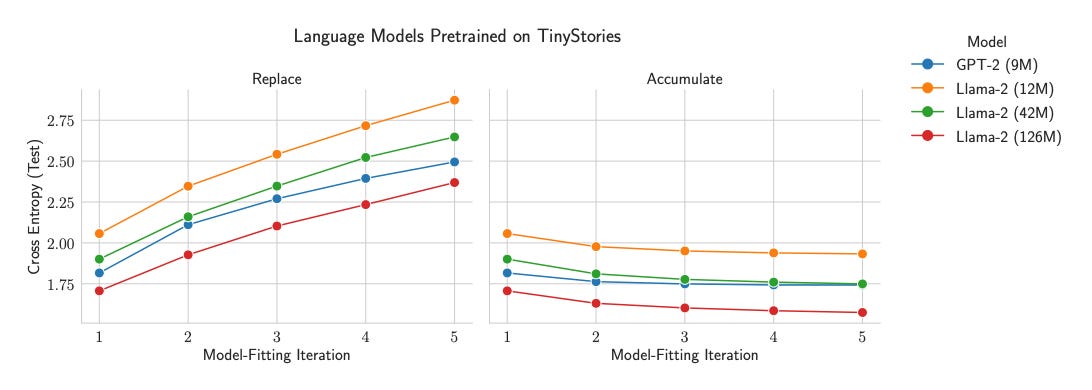
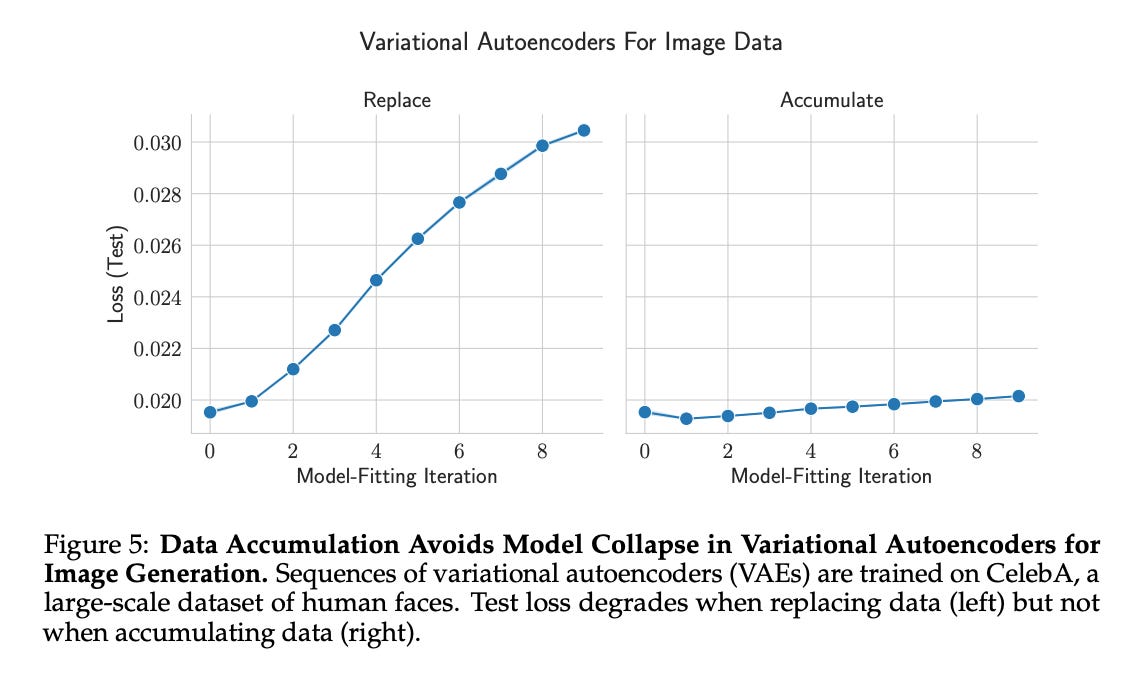
Przykład z generowania obrazów (CelebA): badacze trenowali łańcuch modeli generatywnych na zdjęciach twarzy. Gdy w każdej rundzie treningu zastępowali oryginalne zdjęcia tymi wygenerowanymi przez poprzedni model, po kilku iteracjach twarze zaczęły wyglądać niemal tak samo, model produkował kilka bardzo podobnych typów twarzy i gubił resztę różnorodności. To przypadek model collapse (model zawęża się do kilku wzorców i ignoruje resztę). Gdy zamiast zastępować dane je akumulowano (dokładano syntetyczne dane do tych prawdziwych, stworzonych przez człowieka), różnorodność i jakość pozostały stabilne (czyli na nowych, niewidzianych zdjęciach model nie radził sobie gorzej z każdą kolejną rundą).

W tekście zjawisko bywa jeszcze bardziej zdradliwe: model nie bredzi od razu, tylko zaczyna pisać coraz bardziej uśrednione rzeczy. Różnorodność leksykalna, składniowa i semantyczna spada z rundy treningu na trening modelu, a później przy uczeniu na danych wygenerowanych przez AI mogą pojawiać się już kompletne bzdury (przykład z OPT-125M w sekcji “Model Collapse”: prompt o architekturze → po kilku generacjach wywód o zającach z kolorowymi ogonami).
Dlaczego tak się dzieje? Bo model najlepiej utrwala to, co widzi najczęściej. Gdy uczymy go na wynikach poprzednich modeli, do puli trafia głównie treść średnia, a rzadkie, ale ważne przypadki pojawiają się zbyt rzadko i po prostu wypadają z obiegu. To efekt powtarzanego losowania z małej, mało różnorodnej próbki. Najpierw znikają detale. Z rundy na rundę obraz świata się spłaszcza, a model staje się przewidywalny i ślepy na wyjątki (jak z kserowaniem kserówki: za każdym razem giną drobne szczegóły.)
W sieci jest już mnóstwo treści z AI, więc coraz częściej trafiają one do zbiorów treningowych i coraz trudniej je odsiać. To (jeszcze?) nie katastrofa, ale jeśli nie dokładamy regularnie świeżych, ludzkich danych i nie czyścimy korpusów danych treningowych, ryzyko pogorszenia rośnie z każdą kolejną generacją modelu.
Jak BigTechy próbują temu zapobiegać - znaki wodne dla nas… i dla nich
Google, OpenAI i Microsoft zaczęły znakować generatywne treści: SynthID u Google oraz Content Credentials (C2PA) w obrazach z ChatGPT i w Bing. Oficjalnie chodzi o przejrzystość i walkę z deepfejkami. Jest też praktyczny powód: takie oznaczenia ułatwiają sprawdzenie pochodzenia treści (czy powstała ręcznie, czy wygenerował ją model) i odsiewanie jej na etapie przygotowania danych do treningu. To więc etykieta dla użytkownika i znacznik dla zespołów, które później zbierają i czyszczą dane.
Jest jeszcze jedna rzecz: przy watermarkach tekstowych badania pokazują tzw. radioaktywność. Jeśli ktoś trenuje model na oznaczonym tekście (np. ChatGPT na tekstach wygenerowanych przez Gemini), w późniejszym modelu da się wykryć ślad po tych danych. Porównałbym to do farby znakującej w rzece: pomaga identyfikować, co wróciło do obiegu i odcedzać to przy kolejnych iteracjach.
No, ale watermarki da się usunąć lub obejść. Metadane C2PA znikają przy zrzutach ekranu albo konwersjach zdjęć (np. pobierasz obraz z ChatGPT i przerabiasz go w innym modelu). W tekście wystarczy przepuścić go przez inne AI albo sparafrazować. Wtedy znak wodny znika.
Dlatego obecność watermarków traktowałbym z przymrużeniem oka. Bez niej nadal nie wiemy, skąd pochodzi obraz. Może ktoś wygenerował coś realistycznego z Nano Banana od Google, a potem edytował delikatnie zdjęcie z innym modelem, który nie zostawia znaków wodnych?
Mała kontrowersja: Big Tech nie tylko informuje i dba o bezpieczeństwo użytkowników przed fejkami. Równie mocno zabezpiecza własny łańcuch dostaw danych do treningu modeli, żeby nie zapętlić się na własnych treściach wygenerowanych przez model.
Co to oznacza dla przyszłości AI
Przez lata działała prosta reguła: więcej danych + większe modele = lepsze wyniki. To ujęcie wywodzi się na przykład ze “scaling laws” (Chinchilla), które pokazały, że przy danym budżecie obliczeń warto równomiernie zwiększać liczbę parametrów i liczbę tokenów, i że duża ilość danych naprawdę ma znaczenie. Jednocześnie coraz wyraźniej widać, że liczy się nie tylko ilość, ale jakość i pochodzenie danych.
Model collapse zmienia zasady. Nie chodzi już wyłącznie o “ile masz”, ale “jakie” masz dane. Coraz więcej analiz pokazuje szybki wzrost udziału treści generowanych przez modele w internecie po boomie 2022-2023, co utrudnia budowanie czystych zbiorów danych do kolejnych generacji. Badania mierzące rozprzestrzenianie się treści wygenerowanych przez AI dokumentują stały wzrost takiej treści.
Dziś złotymi danymi są zbiory sprzed masowego zalewu kontentem wygenerowanym przez AI (przed 2022-2023) oraz archiwa, w których jasno wiadomo, skąd pochodzą treści i kto je stworzył. Firmy, które wcześniej zgromadziły duże, dobrze opisane zbiory, mają realną przewagę konkurencyjną.
Co z resztą rynku? Trzeba nauczyć się żyć w nowym reżimie danych: mieszać dane ludzkie z syntetycznymi w kontrolowanych proporcjach, kurować wielkie korpusy danych, dbać o źródło danych (np. przez Content Credentials/C2PA) i filtrować niskiej jakości dane generowane przez AI. To kosztuje i wymaga procesu, ale działa.
Dobra wiadomość jest taka, że katastrofa nie jest nieuchronna. Prace, o których tutaj napisałem pokazują, że jeśli nie zastępujemy danych ludzkich syntetycznymi, tylko je akumulujemy (dokładamy kolejne dane do istniejącej puli realnych danych), to problemy przestają rosnąć z generacji na generację modelu, a więc model collapse nie zachodzi. Kluczowe jest utrzymywanie stałej domieszki prawdziwych danych i kuracja danych syntetycznych.
Najcięższe w tym wszystkim jest to, że wiarygodne, świeże dane od ludzi będą coraz droższe i trudniejsze do pozyskania zarówno z powodu zanieczyszczenia sieci treściami AI, jak i wymogów prawnych/licencyjnych. Dlatego przewaga przesuwa się z “kto ma najwięcej GPU (kart graficznych)” na “kto ma najlepszy łańcuch dostaw danych”.

Niecodzienne porady do najpopularniejszych narzędzi AI.
Dzisiaj mam dla Ciebie porady, które pomogą Ci lepiej wykorzystać narzędzia AI popularne w codziennym użytku. Są to głównie wskazówki wynalezione przez użytkowników lub takie, które są głębiej ukryte w dokumentacji narzędzi.
ChatGPT:
Meta-Prompt Engineering: Napisz "Jesteś moim inżynierem promptów. Chcę osiągnąć [tutaj opisz swój cel]. Zadaj pytania, a następnie wygeneruj zoptymalizowany prompt", aby przekształcić niejasne pomysły w precyzyjne instrukcje, oszczędzając czas na iteracjach. - źródło
Zacznij od "Pomyślmy o tym inaczej" - to pobudza kreatywność modelu. - źródło
Użyj "Czego tutaj nie widzę?" - znajduje martwe punkty i założenia, o których nie wiedziałeś, że istnieją. - źródło
Zapytaj "Co byś zrobił na moim miejscu?" - to sprawia, że przestaje być neutralny i zaczyna wyrażać nieco lepsze opinie. Znacznie bardziej przydatne niż ogólnikowe rady. - źródło
Użyj "Oto o co naprawdę pytam" - dodaj to po każdym pytaniu. "Jak mogę dostać awans? Oto o co naprawdę pytam: jak się wyróżnić, nie będąc irytującym?" - źródło
Zakończ "Co jeszcze powinienem wiedzieć?" - dodaje kontekst i ostrzeżenia, o które nie pomyślałeś zapytać. - źródło
Claude:
W modelach Claude istnieją ukryte poziomy rozumowania sterowane słowami-kluczami. Napisanie fraz “think”, “think hard”, “think harder” czy nawet “ultrathink” w prośbie powoduje przydzielenie modelowi większego budżetu myślowego (więcej tokenów i czasu na rozumowanie). - źródło
Gemini:
Gemini oferuje różne warianty, np. tryb Flash (szybszy, mniejszy model) vs Pro (większy model o wyższej mocy). Mało kto zdaje sobie sprawę, jak bardzo opłaca się dobrać model do zadania. Gemini Pro 2.5 generuje odpowiedzi wyższej jakości i lepiej trzyma się tematu, podczas gdy Gemini Flash 2.5 odpowiada bardziej zwięźle, ale czasem gubi szczegóły lub logikę.
Veo 3:
Przy tworzeniu klipów wideo za pomocą Veo 3 warto używać języka profesjonalistów z branży filmowej. Model ten rozumie wiele koncepcji z zakresu sztuki operatorskiej możesz precyzyjnie zasugerować ujęcia, obiektywy i ruch kamery w promptach. Te prompty możesz wygenerować z jakimkolwiek modelem, pisząc mu “Wciel się w profesjonalistę z branży filmowej”. - źródło
Podglądaj sprawdzone prompty w Flow: Google udostępniło narzędzie Flow jako interfejs do Veo 3, a w nim funkcję Flow TV, bibliotekę przykładowych klipów tworzonych przez społeczność. Mało dokumentowaną sztuczką jest to, że można podejrzeć prompty użyte do wygenerowania tych publicznych filmów. Jeśli nie działa, to spróbuj wejść na tę stronę używająć VPN z lokalizacją na UK lub USA.
Limit znaków w dialogu: utrzymuj wypowiadane kwestie poniżej 120-140 liter na 8-sekundowy klip, aby zachować naturalne tempo rozmów.
Nano Banana (model Gemini generujący obrazy):
Dwufazowa zmiana tła: Nie próbuj od razu podmieniać tła na skomplikowaną scenę. Lepsze efekty da podejście krok po kroku. Użytkownicy odkryli trik: najpierw zamień tło na jednolity kolor (np. zielony lub niebieski), a dopiero w kolejnym żądaniu wprowadź pożądane tło docelowe. - źródło
Aspect ratio: Dodaj do prompta Aspect ratio 16:9 (lub inne jak 9:16, 4:3), aby uzyskać zdjęcie w pożądanych proporcjach.

AI na wynos
🍌 Nano Banana (najnowszy i chyba najlepszy model do generowania obrazów) jest teraz dostępny za darmo na X. Wystarczy go oznaczyć w poście lub komentarzu i wysłać prompt - zobacz.
🍌 Jak promptować Nano Banana? - oficjalny poradnik od Google.
𝕏 Jeden z inżynierów ukradł kod od xAI Elona Muska. Po czym dołączył do OpenAI. Co się z nim teraz dzieje? - czytaj więcej.
🔊 ElevenLabs z nową wersją modelu do generowania efektów dzwiękowych. Według naszych testów dużo lepszy od poprzedniej wersji - zobacz.
📝 PKO wypuściło nowy open-source model reprezentacji tekstu! Poznaj Polish Roberta 8K - czytaj więcej.
🌐 Norton (możesz znać ich antywirusa) tworzy nową przeglądarkę napędzaną AI. Chyba wszyscy się teraz na to rzucają. - zapisz się do waitlisty.
📖 Nowy poradnik od OpenAI: Jak promptować agentów głosowych? - czytaj.
💻 Nowe narzędzie do vibe kodowania/pair programming - Warp Code - czytaj.
🆕 Nowość w OpenRouter. Któraś firma dodała nowe modele do testowania. Na razie są za darmo i wiemy, że mają 2 miliony tokenów kontekstu. - zobacz.
📬 Czytałeś/-aś ostatnie wydanie? Wysłaliśmy je do Ciebie kilka dni temu. Szukaj w skrzynce maila pod tytułem:
“💁🏻♂️🖼 Lepiej zostać historykiem sztuki niż absolwentem informatyki”

What is AI Model Collapse? (in about a minute)
Scientists warn of AI collapse
A jeśli już jesteś subskrybentem i dotarłeś tutaj, oceń treść:
Jeżeli chcesz słuchać treści newsletterów w formie audio, to subskrybuj nasz kanał youtube - gorąco zachęcamy!

Tak jak obiecaliśmy dajemy Wam okazję do tego, abyście mogli dołączyć do naszej społeczności na Discordzie 🔑
Otwieramy drzwi do miejsca, gdzie spotkać możecie ekspertów i prawdziwych entuzjastów sztucznej inteligencji. Zresztą przez wiele miesięcy w tej właśnie sekcji newslettera, opowiadaliśmy kogo możecie na naszym Discordzie spotkać i co możecie tam znaleźć.
ponad 1800 osób
ludzie różnych branż i środowisk
wiele działów tematycznych (AI grafika, AI wideo, AI biznes, AI programowanie, AI książka, AI film, działy AI commentary)
Jest to miejsce, gdzie pasja spotyka się z wiedzą - możecie wymieniać pomysły, uczyć się od liderów branży i budować kompetencje AI razem z nami.
🔑 Co zyskujesz?
Dostęp do ekskluzywnego kanału Discord Horyzont, gdzie toczą się gorące dyskusje, warsztaty i networking z profesjonalistami AI
Dostęp do newsów, inside’ów z branży szybciej niż otrzymasz je w newsletterze lub gdziekolwiek indziej
Dostęp do kanału głosowego na którym co 2 tygodnie spotykamy się i rozmawiamy o AI
Możliwość współtworzenia innowacyjnych projektów i dzielenia się doświadczeniem z pasjonatami AI
🔑Jak dołączyć?
Postanowiliśmy, że dostęp do naszego kanału, który - jesteśmy przekonani - jest fantastycznym miejscem dla rozwoju umiejętności AI każdego zainteresowanego budowaniem swoich kompetencji, będzie dostępem płatnym.
Opłata jest jednak jednorazowa i uprawnia do dożywotniego dostępu - bez miesięcznych subskrypcji. Płacisz raz i jesteś z nami na zawsze!
Możesz potraktować taki zakup nie tylko jako inwestycję w siebie, ale także coś co jest wsparciem dla naszej społeczności i dla horyzont.ai - swoistym 🤝 uściśnięciem dłoni za pracę naszej trójki Jakuba, Oskara i Marcina. Dziękujemy, jeśli się zdecydujesz :)
Jednorazowa płatność to 99 złotych (liftime access)
Wpisz mail, najlepiej ten którym posługujesz się na Discord (jeśli nie masz jeszcze swojego konta, załóż, naprawdę warto korzystać z platformy)
Po opłaceniu wyślemy Ci na e-mail zaproszenie na nasz kanał (proces może chwilę potrwać, ale uczynimy to niezwłocznie po otrzymaniu informacji o zakupie dostępu)
Nie przegap szansy na dołączenie do naszej społeczności. Zainwestuj w swoją pasję już dziś, ucz się i nawiąż nowe znajomości w branży. Gorąco zapraszamy!
Dzięki za przeczytanie tego wydania newslettera Horyzont AI!
- @OskarKorszeń @MarcinUszyński @JakubNorkiewicz
Jeśli jesteś tu pierwszy raz - dołącz za darmo, aby regularnie otrzymywać takie treści na swojego maila.
Dzięki za kolejne wydanie. Wydaje mi się jednak, że collapse nie powinien być rezerwowany tylko i wyłącznie dla LLMów. Jeszcze przed erą AI często można było usłyszeć o recyklingu treści. Lubimy piosenki które znamy. Książki samorozwojowe wydają się być w kółko o tym samym. Poradniki biznesowe oparte na antycznej "Sztuce Wojny". Na 1000 dzieł popkultury pojawia się jedno naprawdę kreatywne. Bez "Rodziny Soprano" nie byłoby Breaking Bad i wielu innych, gorszych seriali. Kopie robione od kopii i związany z tym spadek jakości towarzyszy cywilizacji od zawsze.
Ok. Wykres dotyczy tego jak ktoś mówi, ale niekoniecznie CO mówi. Chociaż żyjąc w UK od półtora dekady podejrzewam, że wielu MPs szuka tam też porady co myśleć/powiedzieć.
Mój poprzedni komentarz pokazuje tylko, że collapse nam towarzyszy od zawsze. Warto się zastanowić nad poziomem kreatywności ludzi vs AI. Bo to kreatywność jest siłą powstrzymującą spadek jakości. Collapse w AI będzie dotkliwszy bo kreatywność ludzka jest większa niż maszynowa. Kreatywność w AI bazuje na kompilacji. Tworzenie nowych rzeczy przez łączenie czegoś co już istnieje. Algorytmy stworzą obrazek kota surfujacego na desce ucząc się na bazie danych obrazków z surferami i kotami. Człowiek też kompiluje, ale wydaje mi się, że ludzkość ma jednostki, których kreatywne przebłyski to zupełnie inny poziom, nie oparty tylko na kompilacji. Coś czego AI jeszcze nie potrafi. AI nie rozwiązuje problemów kreatywnością (co zdarza się ludziom) tylko rozpoznaje patterny i bazuje na statystyce w źródłach. Dlatego collapse to większy problem dla AI niż dla ludzi. Może warto poświęcić jakiś wpis kreatywności AI? Chętnie o tym u was przeczytam.