
LLM-y Dyfuzyjne (dLLM): Nowa architektura w generowaniu tekstu
🤖 Budowanie agentów AI na Google Cloud Platform - wprowadzenie


🔉Wolisz wersję audio? Nie możesz przeczytać teraz maila?
Przesłuchaj tutaj
Możesz nas słuchać także na Apple Podcast i Spotify.
🎯W DZISIEJSZYM WYDANIU
🎓 AI od zera do zrozumienia: Czy AI może tworzyć tekst inaczej niż słowo po słowie?
🛠 AI w praktyce: 🤖 Budowanie agentów AI na Google Cloud Platform - wprowadzenie
🥡 AI na Wynos:
🤖 Jeśli oznaczysz Groka na X.com z promptem “narysuj mnie”, to w końcu odpowiada zdjęciem
🤖 OpenAI z nowymi modelami o3 i o4-mini…znowu zaskoczyli ludzi
💻 OpenAI chce kupić Twój ulubiony edytor do vibe kodowania
🧠 Chcesz się nauczyć Reinforcement Learning?
🤖 CEO Perplexity pokazuje co będzie potrafiła jego AI przeglądarka
🤖 Badacze umieścili 1 000 agentów AI na serwerze Minecraft, a oni
wykształcili własną cywilizację z rządem, kulturą i gospodarką
💻 OpenAI z odpowiedzią na Claude Code
📚 Rekomendowana Biblioteka:
Nie, Shen, et al. "Large language diffusion models."
Introducing Mercury, the first commercial-scale diffusion large language model.

Czy AI może tworzyć tekst inaczej niż słowo po słowie?
Większość interakcji z obecnymi systemami AI generującymi tekst, jak modele z rodziny GPT, opiera się na paradygmacie autoregresywnym. Oznacza to, że tekst jest generowany sekwencyjnie - model przewiduje kolejne słowo (lub token) bazując na sekwencji słów wygenerowanych do tej pory. Ten proces, przypominający budowanie zdania krok po kroku, zdominował rozwój dużych modeli językowych LLM.
Naturalne staje się jednak pytanie: czy jest to jedyna skuteczna metoda generowania tekstu przez AI? Czy istnieją alternatywne architektury, które mogłyby podejść do tego zadania w inny sposób?
Odpowiedź brzmi: tak. Coraz większą uwagę zyskują modele dyfuzyjne. Technika ta zyskała rozgłos dzięki swoim sukcesom w dziedzinie generowania obrazów. Modele takie jak Stable Diffusion, MidJourney czy DALL-E wykorzystują proces polegający na stopniowym usuwaniu szumu z początkowego, losowego sygnału, aby finalnie uzyskać spójny i realistyczny obraz. To właśnie ta zdolność do rzeźbienia struktury z chaosu okazała się niezwykle potężna.
Obecnie trwają intensywne prace nad adaptacją tej samej koncepcji do dziedziny języka naturalnego, który charakteryzuje się danymi o charakterze kategorycznym lub sekwencyjnym. Przeniesienie jej nie jest proste, ale pierwsze wyniki i powstające modele wskazują na obiecujący kierunek rozwoju.
W tym wydaniu przyjrzę się bliżej modelom dyfuzyjnym w kontekście generowania tekstu. Postaram się odpowiedzieć na kluczowe pytania:
Jaka jest podstawowa zasada działania modeli dyfuzyjnych w zastosowaniu do języka?
Jakie są fundamentalne różnice między tym podejściem a modelami autoregresywnymi?
Jakie możliwości i potencjalne przewagi oferują modele dyfuzyjne dla tekstu?
Z jakimi wyzwaniami mierzą się te modele i jakie są ich obecne ograniczenia?
Czy mają potencjał, by stać się realną alternatywą lub uzupełnieniem dla obecnych LLM-ów?
Sztuka z szumu: Jak działają modele dyfuzyjne
Aby zrozumieć, jak modele dyfuzyjne podchodzą do generowania tekstu, warto najpierw przyjrzeć się ich działaniu w dziedzinie, gdzie odniosły spektakularny sukces - generowaniu obrazów. Tam koncepcja jest bardziej wizualna i intuicyjna.
Podstawowa idea działania modeli dyfuzyjnych opiera się na dwóch kluczowych procesach:
Proces "Do Przodu" (Forward Process - Noising): wyobraź sobie, że masz czysty, wyraźny obraz. W tym etapie systematycznie, krok po kroku, dodajesz do niego niewielkie ilości losowego szumu (przypominającego śnieżenie na starym telewizorze). Powtarzasz ten krok wielokrotnie (np. setki lub tysiące razy). Z każdym krokiem obraz staje się coraz bardziej zamazany i chaotyczny, aż w końcu, na samym końcu tego procesu, otrzymujesz coś, co jest praktycznie nieodróżnialne od czystego, losowego szumu. Ważne jest to, że sposób dodawania szumu jest precyzyjnie zdefiniowany - wiesz dokładnie, jak obraz jest "psuty" na każdym etapie.
Proces "Do Tyłu" (Reverse Process - Denoising): tutaj wkracza sztuczna inteligencja. Model (najczęściej sieć neuronowa) jest trenowany, aby nauczyć się odwracać proces opisany powyżej. Jego zadaniem jest, zaczynając od obrazu będącego czystym szumem, stopniowo usuwać ten szum, krok po kroku, przewidując, jak wyglądał obraz na poprzednim, nieco mniej zaszumionym etapie. Sieć uczy się rozpoznawać wzorce ukryte w szumie i przewidywać, jaki czystszy stan doprowadził do obecnego, zaszumionego.
Generowanie nowego obrazu polega na uruchomieniu nauczonego procesu "do tyłu". Zaczynamy od zupełnie nowego, losowo wygenerowanego szumu i pozwalamy modelowi iteracyjnie go odszumiać. Krok po kroku, model przekształca ten początkowy chaos w spójną strukturę, aż po wielu iteracjach wyłania się nowy, realistycznie wyglądający obraz, zgodny z tym, czego model nauczył się na danych treningowych.

Można to wizualizować jako proces stopniowego przywracania detali na bardzo zaszumionej fotografii, gdzie każda iteracja ujawnia więcej szczegółów. Kluczowe jest to, że model nie generuje obrazu w jednym kroku, ale poprzez serię iteracyjnych udoskonaleń, zaczynając od całkowitej losowości.
Właśnie ta zdolność do nauki procesu odwracania chaosu i iteracyjnego budowania struktury z szumu jest fundamentem modeli dyfuzyjnych. Teraz spróbujmy zrozumieć, jak tę ideę przeniesiono do świata tekstu.
Generowanie krok po kroku vs ciągłe ulepszanie: Dyfuzja kontra (nie)zwykłe LLM-y
Główna różnica między modelami dyfuzyjnymi a tradycyjnymi dużymi modelami językowymi (jak GPT) leży w fundamentalnie odmiennym sposobie konstruowania tekstu.
Modele tradycyjne (autoregresyjne):
Działają sekwencyjnie. Można je porównać do budowania zdania lub akapitu słowo po słowie, od lewej do prawej. Aby wygenerować następne słowo, model patrzy na słowa, które już napisał. Wybór kolejnego słowa opiera się wyłącznie na tej poprzedzającej sekwencji. Gdy słowo zostanie wybrane, proces przechodzi do następnego kroku. Decyzje podjęte na wcześniejszych etapach wpływają na kolejne, ale model nie wraca, by poprawić już wygenerowane fragmenty w trakcie tego samego procesu generowania.
Modele dyfuzyjne:
Tutaj proces wygląda inaczej. Zamiast generować tekst słowo po słowie, modele dyfuzyjne stosują iteracyjne udoskonalanie. Zaczynają od czegoś, co reprezentuje całą docelową sekwencję tekstu, ale w stanie bardzo "surowym" lub "niekompletnym". Można to sobie wyobrazić jako:
Sekwencję pełną symboli zastępczych (np. `[MASK] [MASK] ... [MASK]`), odpowiadającą długości tekstu, który ma powstać.

Albo jako rozmytą reprezentację znaczeniową całego zdania czy akapitu.
Następnie, w serii wielu kroków (iteracji), model stopniowo udoskonala tę początkową, niekompletną reprezentację. Na każdym kroku przygląda się całej sekwencji w jej obecnym stanie i decyduje, jak ją naprawić lub ulepszyć, aby była bliższa sensownemu, dobrze napisanemu tekstowi.
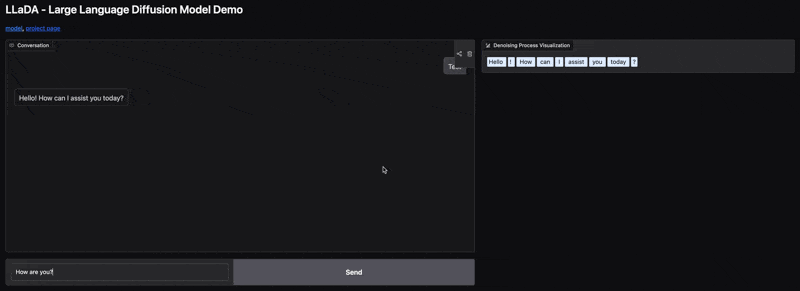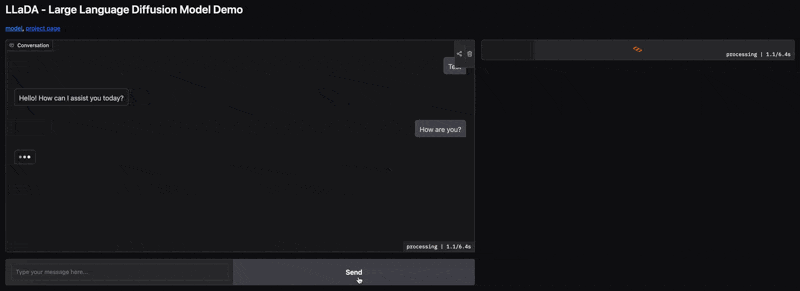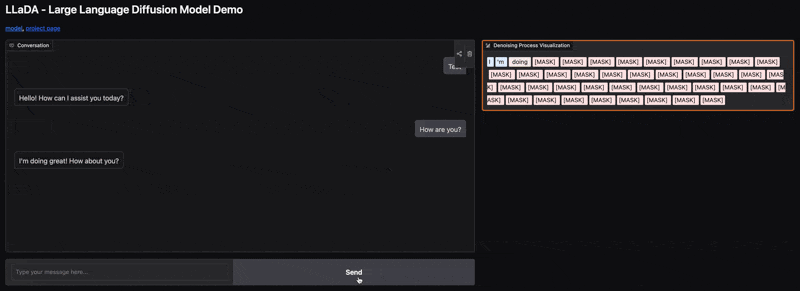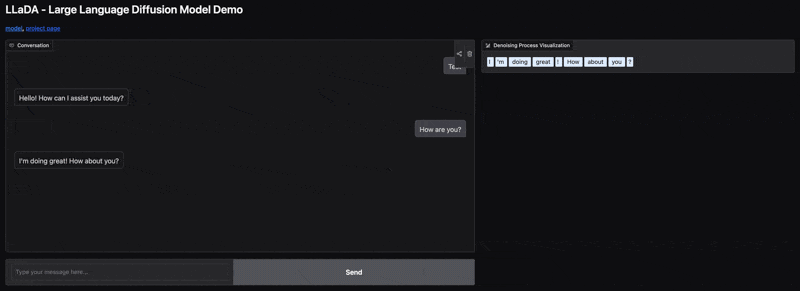
Jeśli zaczynał od symboli `[MASK]`, w każdej iteracji może odkrywać lub precyzować niektóre z tych symboli, zastępując je konkretnymi słowami.
Jeśli zaczynał od rozmytej reprezentacji, każda iteracja może ją wyostrzać, przybliżając do konkretnych słów i struktur gramatycznych.
Analogia: Pomyślmy o rzeźbiarzu. Model autoregresywny jest jak ktoś, kto dodaje kolejne małe kawałki gliny, tworząc figurę od podstawy w górę. Model dyfuzyjny jest bardziej jak rzeźbiarz pracujący nad całym blokiem kamienia - na początku ma tylko ogólny zarys, a potem, w kolejnych etapach pracy, stopniowo usuwa materiał i dodaje detale, aż wyłoni się ostateczna forma. Cały czas pracuje z całością dzieła.
Kluczowa różnica tkwi więc w tym, że modele dyfuzyjne operują i udoskonalają reprezentację całego tekstu jednocześnie przez wiele kroków, podczas gdy modele autoregresyjne budują tekst sekwencyjnie, element po elemencie. Ten odmienny mechanizm ma istotne konsekwencje, zarówno jeśli chodzi o potencjalne zalety, jak i wady tego podejścia, o czym powiem w kolejnych sekcjach.
Co już potrafią? LLaDA, Mercury i potencjał dyfuzji w tekście
Modele dyfuzyjne dla tekstu to już nie tylko koncepcje teoretyczne czy małe eksperymenty. Na scenie pojawiają się konkretne implementacje, które demonstrują praktyczny potencjał tej technologii. Oto dwa znaczące przykłady:
1. LLaDA (Large Language Diffusion with mAsking): Ten model jest przykładem podejścia opartego na maskowaniu (jedna z metod radzenia sobie z dyskretną naturą tekstu). LLaDA została stworzona z ambicją pokazania, że modele dyfuzyjne mogą konkurować z popularnymi modelami autoregresywnymi. Badacze wytrenowali wersje LLaDA sięgające 8 miliardów parametrów i twierdzą, że osiągają one wyniki porównywalne z silnymi modelami typu LLaMA 8B w zadaniach wymagających rozumienia kontekstu. Model LLaDA po odpowiednim dostrojeniu (tzw. fine-tuning na instrukcjach) wykazuje również zdolność do podążania za poleceniami, generowania kodu czy prowadzenia dialogu. Co ciekawe, twórcy sugerują, że architektura dyfuzyjna może lepiej radzić sobie z niektórymi specyficznymi problemami, z którymi zmagają się tradycyjne modele.

2. Mercury (od Inception Labs): Mercury to przykład modelu dyfuzyjnego (dLLM) rozwijanego z myślą o zastosowaniach komercyjnych przez startup Inception Labs. Głównym atutem, na który zwracają uwagę twórcy, jest znacząca przewaga w szybkości i efektywności generowania tekstu. Według Inception Labs, Mercury może generować tekst nawet 5-10 razy szybciej niż zoptymalizowane modele autoregresywne, osiągając prędkości przekraczające 1000 tokenów na sekundę na standardowych kartach GPU. Przekłada się to na niższe opóźnienia i potencjalnie niższe koszty operacyjne. Dostępna jest specjalizowana wersja Mercury Coder do generowania kodu, a model jest wdrażany w takich obszarach jak obsługa klienta czy automatyzacja w firmach.

Oprócz potencjalnej szybkości czy konkurencyjnej jakości, modele dyfuzyjne oferują jeszcze jedną, często podkreślaną zaletę: zwiększoną kontrolowalność. Ich iteracyjny proces udoskonalania stwarza naturalne punkty, w których można wpływać na generowany tekst. Wyobraźmy sobie możliwość kierowania procesu generowania w stronę określonego stylu, tonu, tematu czy nawet struktury gramatycznej, potencjalnie z większą elastycznością niż w przypadku modeli autoregresywnych, które często wymagają starannego przygotowania promptu lub dodatkowego trenowania. Ta cecha może być szczególnie cenna w zastosowaniach wymagających precyzyjnego kształtowania wyniku.
---
Gdzie tkwi haczyk? Wyzwania i obecne ograniczenia
Mimo obiecujących możliwości, modele dyfuzyjne dla tekstu nie są jeszcze rozwiązaniem pozbawionym wad i stoją przed nimi istotne wyzwania. Ważne jest, aby spojrzeć na nie realistycznie:
Szybkość - sprawa bardziej złożona niż się wydaje: Chociaż modele takie jak Mercury chwalą się dużą prędkością, obraz jest bardziej skomplikowany. Owszem, w pojedynczym kroku procesu generowania, model dyfuzyjny może przetwarzać wiele (lub wszystkie) tokeny jednocześnie (równolegle), co jest szybsze niż sekwencyjne generowanie słowo po słowie w modelach autoregresywnych. Jednak cały proces generowania tekstu przez dyfuzję wymaga wielu takich kroków (iteracji udoskonalania) - czasami dziesiątek, setek, a we wczesnych modelach nawet tysięcy. Całkowity czas generowania zależy więc od liczby tych kroków. Trwają intensywne badania nad zmniejszeniem liczby potrzebnych iteracji bez utraty jakości, ale często występuje tu kompromis: mniej kroków może oznaczać szybsze generowanie, ale potencjalnie gorszy tekst. Dlatego twierdzenia o 5-10x większej szybkości trzeba traktować z uwzględnieniem kontekstu - mogą być prawdziwe w niektórych scenariuszach, ale niekoniecznie uniwersalnie.
Jakość tekstu: historycznie, modele dyfuzyjne miały trudności z dorównaniem jakością tekstu (mierzoną np. standardowymi metrykami jak płynność czy spójność logiczna) najlepszym modelom autoregresywnym. Chociaż najnowsze modele, jak LLaDA, pokazują, że **różnica ta maleje**, nadal istnieje pewien dystans do czołówki. Osiągnięcie najwyższej jakości, zwłaszcza w zadaniach wymagających precyzji na poziomie całej sekwencji (np. logiczne rozumowanie), może wymagać większej liczby kroków dyfuzji, co z kolei wpływa na wspomnianą wcześniej szybkość.
Skalowalność: obecnie rozwijane modele dyfuzyjne są z reguły mniejsze niż największe modele autoregresywne (np. LLaDA 8B vs modele rzędu setek miliardów czy bilionów parametrów jak GPT-4o). Pozostaje otwartym pytaniem, czy modele dyfuzyjne będą **skalować się równie efektywnie**, tzn. czy ich jakość będzie równie przewidywalnie rosła wraz ze zwiększaniem rozmiaru modelu i ilości danych treningowych, jak ma to miejsce w przypadku modeli typu GPT. Trenowanie bardzo dużych modeli dyfuzyjnych od zera jest również bardzo kosztowne obliczeniowo.
Złożoność: sam proces trenowania modeli dyfuzyjnych może być bardziej skomplikowany i wymagać starannego doboru wielu parametrów (np. harmonogramu dodawania szumu). Również sam mechanizm generowania (wiele kroków, odszumianie/odmaskowywanie) jest mniej intuicyjny niż proste generowanie słowo po słowie.
Po co nam to wszystko? Przyszłość tekstu tworzonego przez dyfuzję
Skoro modele dyfuzyjne mają swoje wyzwania, dlaczego w ogóle warto się nimi interesować i śledzić ich rozwój? Odpowiedź leży w ich unikalnym potencjale, wynikającym wprost z odmiennego mechanizmu działania:
Potencjał do lepszej spójności i długoterminowego kontekstu: ponieważ modele dyfuzyjne pracują nad całą sekwencją jednocześnie w procesie iteracyjnego udoskonalania, mają teoretyczną przewagę w widzeniu całościowego obrazu tekstu. Może to prowadzić do generowania dłuższych tekstów o lepszej spójności i lepiej zachowanych zależnościach między odległymi fragmentami - problemie, z którym modele autoregresywne często się zmagają.
Zaawansowana kontrola i elastyczność: jak wspomniałem, iteracyjny charakter dyfuzji otwiera drzwi do bardziej elastycznego sterowania procesem generowania. To nie tylko kontrola nad stylem czy tematem, ale również naturalne dopasowanie do zadań takich jak edycja tekstu czy uzupełnianie luk (infilling), które są mniej naturalne dla modeli generujących ściśle od lewej do prawej. Daje to nadzieję na stworzenie bardziej precyzyjnych narzędzi do pracy z tekstem.
Klucz do systemów multimodalnych? Modele dyfuzyjne już udowodniły swoją siłę w generowaniu obrazów, wideo i audio. Ich zdolność do operowania na różnych typach danych (po odpowiedniej adaptacji) czyni je silnym kandydatem do budowy przyszłych, prawdziwie zintegrowanych systemów multimodalnych, które potrafią płynnie rozumieć i generować kombinacje tekstu, obrazu i dźwięku w ramach jednego, spójnego modelu.
Podsumowując: nowa droga dla AI?

Dyfuzyjne duże modele językowe stanowią alternatywę dla dominującego podejścia autoregresywnego (jak w GPT). Zamiast generować tekst słowo po słowie, działają poprzez iteracyjne udoskonalanie, zaczynając od surowej lub zaszumionej reprezentacji całej docelowej sekwencji i stopniowo ją naprawiając.
Ten odmienny mechanizm przynosi ze sobą zestaw unikalnych potencjalnych zalet, takich jak większa elastyczność w generowaniu (np. łatwość edycji czy uzupełniania tekstu), obiecujące możliwości precyzyjnej kontroli nad wynikiem, a także teoretyczny potencjał do lepszego zarządzania globalną spójnością tekstu. Przyciąga również uwagę potencjalną efektywnością w niektórych zastosowaniach.
Jednocześnie, modele te mierzą się z własnymi wyzwaniami. Kwestia rzeczywistej szybkości generowania jest złożona (zależy od liczby kroków), jakość tekstu wciąż często ustępuje najlepszym modelom autoregresywnym (choć różnica maleje), a ich skalowalność i złożoność treningu pozostają obszarami aktywnych badań.
Modele dyfuzyjne nie są (jeszcze?) uniwersalnym zastępstwem dla dobrze znanych LLM-ów. Są raczej inną ścieżką rozwoju, oferującą odmienny zestaw kompromisów i możliwości. Ich unikalne właściwości, szczególnie sukcesy w innych domenach (obrazy, audio) i naturalna skłonność do kontroli, sprawiają, że jest to kierunek warty podjęcia.
Warto mieć je na oku. Obserwowanie, jak badacze radzą sobie z wyzwaniami i jak wykorzystują unikalne zalety dyfuzji, może dać nam wgląd w przyszłe kierunki ewolucji sztucznej inteligencji, zwłaszcza w obszarach wymagających złożonej syntezy i multimodalności. To może być ważny element przyszłego krajobrazu AI.

🤖 Budowanie agentów AI na Google Cloud Platform - wprowadzenie
❗️Ważna informacja na start o korzystaniu z Google Cloud
Google Cloud to płatna platforma chmurowa, ALE❗️wiele jej funkcjonalności możesz wypróbować bez opłat. Część opcji, np. przeglądanie interfejsu czy testowanie niektórych usług w ograniczonym zakresie, jest dostępna za darmo.
Ponadto otrzymasz 300 USD na start – dla chętnych do testów:
Jeśli zechcesz testować usługi Google, to gigant oferuje 300 USD do wykorzystania przez 90 dni dla nowych użytkowników. Wymaga to podpięcia karty płatniczej, ale bez Twojej zgody żadne dodatkowe opłaty nie zostaną naliczone po wykorzystaniu środków!
-
Jak stworzyć swojego agenta?
Wejdź na stronę Google Cloud i zarejestruj bezpłatne konto:

Po utworzeniu konta w konsoli otwórz menu nawigacyjne 🍔 po lewej stronie i kliknij w kafelek “wszystkie aplikacje” na samym dole listy - następnie znajdź sekcję “sztuczna inteligencja” - wybierz zakładkę “AI aplikacje”.
Na kolejnej stronie znajdź kafelek “Agentów konwersacyjnych” i wcinij “Create”

Wybierz w okienku opcję “Build your own”, choć możesz wykorzystać predefiniowanych agentow stworzonych przez Google (opcja 1) lub agenta odpowiadającego na pytania Q&A z samouczka umieszczonego na Twojej stronie (opcja 3).

Nazwij i skonfiguruj agenta, wybierz opcję “Playbook” i utwórz

W kolejnym oknie musisz opisać cele do jakich powołałeś do życia Agenta (np. jesteś agentem obsługującym firmę XYZ), daj mu krótkie instrukcje (np. przywitaj się i zapytaj w czym możesz pomóc) oraz klikając na button "+ Data store” dostarcz mu wiedzy, z której ma czerpać.


Aby stworzyć bazę wiedzy Twojego agenta uzupełniasz ją o kontekst:
stronę internetową, którą ma analizować (np. adres twojego sklepu online)
pliki które wgrasz (np. FAQ, cennik)
API

Jeżeli już wypełniłeś agenta wiedzą, zapisz dane, ale nie poprzestawaj tylko na tym - powinieneś przeszkolić swojego agenta przeprowadzając z nim rozmowy symulacyjne, które później wykorzysta, gdy przyjdzie mu rozmawiać z Twoimi klientami. Szkolenie możesz wykonać klikając ikonkę 💬 w prawym górnym rogu konsoli konfiguracyjnej, a następnie “create example”.

Brawo! Stworzyłeś Agenta! Jednak pamiętaj, możesz uczynić go jeszcze bardziej pomocnym np. może wysyłać jeszcze maila z ofertą tuż po rozmowie z klientem - można to zrobić poprzez Cloude Run Funcion lub od razu utworzyć Agenta, który wysyła maile, bez wchodzenia w konwersację z klientem.
Na koniec pozostaje Ci zaimplementować Twojego Agenta. Zrobisz to klikając “Integrationts”.

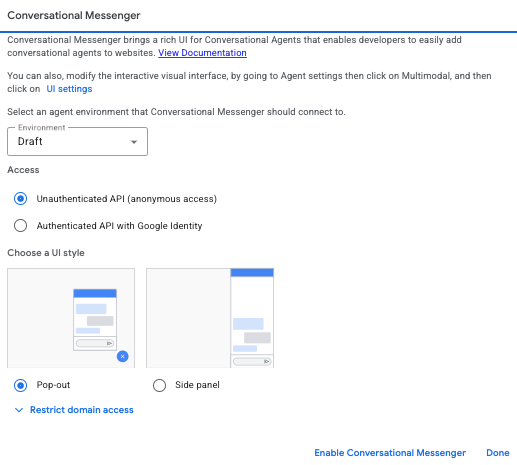
Wybierz np.👆🏻 kafelek “Conversational Messenger” (to klasyczny czat na stronie) i zdecyduj jak czatbot będzie wyglądał na stronie (np. popup), a następnie pobierz kod i zaimplementuj na stronie.
🔗 Chcę spróbować stworzyć swojego agenta AI

🥡 AI na Wynos - nowości AI
🤖 Jeśli oznaczysz Groka na X.com z promptem “narysuj mnie”, to w końcu odpowiada zdjęciem → zobacz
🤖 OpenAI z nowymi modelami o3 i o4-mini…znowu zaskoczyli ludzi → zobacz
💻 OpenAI chce kupić Twój ulubiony edytor do vibe kodowania → zobacz
🧠 Chcesz się nauczyć Reinforcement Learning? → zobacz gdzie zacząć
🤖 CEO Perplexity pokazuje co będzie potrafiła jego AI przeglądarka → zobacz
🤖 Badacze umieścili 1 000 agentów AI na serwerze Minecraft, a oni wykształcili własną cywilizację z rządem, kulturą i gospodarką → zobacz
💻 OpenAI z odpowiedzią na Claude Code → zobacz
📬 Czytałeś/-aś wydanie z 16.04? Treść “💯 najczęstszych przypadków użycia generatywnej AI” trafiła na Twój mail w minioną środę. Sprawdź skrzynkę.


Nie, Shen, et al. "Large language diffusion models." arXiv preprint arXiv:2502.09992 (2025). → https://arxiv.org/abs/2502.09992
Introducing Mercury, the first commercial-scale diffusion large language model → https://www.inceptionlabs.ai/news
- @MarcinUszyński @JakubNorkiewicz
Jeśli jesteś tu pierwszy raz - dołącz za darmo, aby regularnie otrzymywać takie treści na swojego maila.
A jeśli już jesteś subskrybentem i dotarłeś tutaj, oceń treść.
Jeżeli chcesz słuchać treści newsletterów w formie audio, to subskrybuj nasz kanał youtube - gorąco zachęcamy!

