
Czy AI naprawdę myśli? Krytyczne spojrzenie na modele myślące
🐛🦋 Inteligentna transformacja biznesu z AI


🔉Wolisz wersję audio? Nie możesz przeczytać teraz maila?
Przesłuchaj tutaj
Możesz nas słuchać także na Apple Podcast i Spotify.
🎯 W DZISIEJSZYM WYDANIU
🎓 AI od zera do zrozumienia: Czy AI naprawdę myśli? Krytyczne spojrzenie na modele myślące
🛠 AI w praktyce: 🐛🦋 Inteligentna transformacja biznesu z AI

🥡 AI na Wynos:
👑 Polska “AI Gra o Tron”
😱 Grozi nam krach na rynku pracy. Ale nie to jest najgorsze…
🇵🇱 Nowa Polityka AI
🌐 Nowa strona internetowa rządowego portalu sztucznej inteligencji
🇩🇪 Sztuczna inteligencja na niemieckim rynku pracy
🎓 Podsumowanie 5. miesięcy nauki w prywatnej szkole AI
🥩 Co ma wspólnego sztuczna inteligencja z mięsem?
🔬 Jak sztuczna inteligencja wpływa na świat badań i rozwoju
♉️ AI vs. rak prostaty
⚽️ Sztuczna inteligencja znów wchodzi na boiska. Będzie wykrywać spalonego.
🏦 Sztuczna inteligencja w bankach. Klienci wciąż wolą obsługę człowieka.
🔍💸 Wszyscy użytkownicy Perplexity mają dostęp do danych SEC - dostęp do kompleksowych danych finansowych.
🔞 Wygenerowali pornografię AI, wykorzystując wizerunek koleżanki. Policja zbada sprawę.
🦮 Sztuczna inteligencja i ochrona zwierząt: sojusznik czy zagrożenie?
🦾 Bioniczne ramię.
📖 Sztuczna inteligencja rozwikłała sekrety Biblii.
📕 Książka napisana za pomocą sztucznej inteligencji.
📚 Rekomendowana Biblioteka:
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
“How I Use LLMs?” film Andreja Karpathyego


"Czy maszyny mogą myśleć?" - to pytanie, niczym bumerang, powraca w dyskusjach o sztucznej inteligencji od dekad. Odpowiedź, jak to często bywa z wielkimi pytaniami, jest... cóż, skomplikowana i wielowymiarowa. Przyznam szczerze, że zanim natrafiłem na badanie, którym chcę się dziś z Tobą podzielić, sam byłem skłonny wierzyć, a może nawet miałem nadzieję, że jesteśmy już o krok dalej. Że najnowsze modele językowe, zwłaszcza te trenowane za pomocą zaawansowanych technik, zaczynają wykazywać zalążki czegoś więcej niż tylko wyrafinowanego dopasowywania wzorców. Jedną z technologii, która szczególnie mocno rozpalała wyobraźnię w kontekście uczenia myślenia, zwłaszcza w dziedzinach wymagających ścisłej logiki jak matematyka czy programowanie, jest RLVR. To podejście, gdzie model uczy się poprzez weryfikowalne nagrody, maluje wizję AI, która samodzielnie ewoluuje swoje strategie rozumowania, stając się coraz lepsza nie tylko w znanych zadaniach, ale i w odkrywaniu nowych ścieżek (patrz modele serii “O” od OpenAI, Thinking od Anthropic, Grok 3, Gemini 2.5 Pro/Gemini 2.5 Flash). Brzmi jak scenariusz niemal idealny, prawda?
Obietnica RLVR - AI, która sama się uczy?
Pewnie nieraz zastanawiałeś się, jak to jest, że sztuczna inteligencja potrafi grać w szachy lepiej niż arcymistrzowie, albo samodzielnie odkrywać strategie w skomplikowanych grach, takich jak Go. Kluczem często jest tu podejście znane jako Reinforcement Learning (RL), czyli uczenie przez wzmacnianie.
Przypomnienie Reinforcement Learning: Wyobraź sobie, że tresujesz psa: za każdym razem, gdy wykona sztuczkę poprawnie, dostaje smakołyk. AI w RL działa na podobnej zasadzie - otrzymuje wirtualne nagrody za działania, które przybliżają je do celu (dobrej odpowiedzi), i metodą prób i błędów uczy się, jakie strategie są najskuteczniejsze.
A teraz przenieś ten pomysł na grunt wielkich modeli językowych. Można je w podobny sposób trenować w sztuce rozumowania? I tu właśnie na scenę wkracza RLVR, czyli Reinforcement Learning with Verifiable Rewards - Uczenie przez Wzmacnianie z Weryfikowalnymi Nagrodami.
Weryfikowalne nagrody to kluczowy element. Oznaczają one, że mamy jasny, zero-jedynkowy sposób, aby stwierdzić, czy model dobrze wykonał zadanie. Jeśli poprosisz go o rozwiązanie zadania matematycznego, odpowiedź jest albo prawidłowa, albo nie. Nie ma tu miejsca na prawie dobrze. Jeśli model ma napisać fragment kodu, to albo ten kod działa i przechodzi testy, albo nie. To proste i jednoznaczne kryterium oceny.
Dzięki temu mechanizmowi, RLVR miało stać się prawdziwym przełomem. Panowało - i myślę, że w wielu kręgach nadal panuje - głębokie przekonanie, że to właśnie ta technika pozwoli modelom językowym nie tylko na doskonalenie znanych już umiejętności, ale na autonomiczne odkrywanie zupełnie nowych wzorców rozumowania, nowych sposobów dochodzenia do rozwiązań.
Wizja była - i jest - niezwykle kusząca: AI, które dzięki RLVR nieustannie się samodoskonali, przekracza swoje początkowe ograniczenia i wznosi się na coraz wyższe poziomy abstrakcyjnego myślenia. Kto z nas nie chciałby być świadkiem narodzin takiej inteligencji?
Zagadka "Zdolności Rozumowania" - Jak to zmierzyć?
No dobrze, mamy więc na horyzoncie technologię RLVR, która obiecuje nauczyć modele myśleć w nowy, bardziej elastyczny sposób. Ale jak właściwie sprawdzić, czy ta obietnica jest spełniana? Skąd możesz wiedzieć, że model faktycznie rozwinął jakąś nową, fundamentalną zdolność rozumowania, a nie po prostu miał farta przy jednym konkretnym zadaniu? Albo, co równie istotne, skąd masz pewność, że model czegoś nie potrafi, a nie zwyczajnie nie miał dobrego dnia albo odpowiedniego natchnienia przy tej jednej, jedynej próbie, na którą mu pozwoliłeś?
Tradycyjne metody oceny modeli językowych często opierają się właśnie na takim pojedynczym podejściu: dajesz modelowi zadanie i sprawdzasz, czy odpowiedział poprawnie. Jeśli tak - świetnie. Jeśli nie - cóż, może nie jest aż tak bystry, jak sądziliśmy (wiele osób po takich próbach kompletnie rezygnuje z korzystania z AI 😅). Ale czy takie podejście jest do końca miarodajne, gdy chcemy zbadać granice jego możliwości? Pomyśl o sobie - czy zawsze rozwiązujesz skomplikowany problem matematyczny albo piszesz idealny fragment kodu za pierwszym podejściem? Czasem potrzebujesz kilku prób, chwili refleksji, może nawet spojrzenia na zagadnienie z zupełnie innej perspektywy.
I tu właśnie na scenę wkracza metryka, która odgrywa kluczową rolę w badaniu, o którym Ci opowiem. Nazywa się ona pass@k (czytaj: "pass at k"). Brzmi trochę technicznie, ale idea jest naprawdę prosta i intuicyjna.
Wyobraź sobie, że zamiast dawać modelowi tylko jedną szansę na rozwiązanie problemu, dajesz mu ich k. To k może oznaczać 5 prób, 10, a w przypadku omawianych badań nawet 100, 256 lub więcej! Jeśli modelowi uda się wygenerować poprawną odpowiedź (np. prawidłowe rozwiązanie zadania matematycznego lub działający kod) choćby w jednej z tych k prób, uznajemy, że ten konkretny problem jest w jego zasięgu, czyli, że model potencjalnie jest w stanie go rozwiązać. Wartość pass@k dla całego zestawu testowego mówi nam wtedy, jaki procent problemów model potrafi zaliczyć, jeśli damy mu właśnie k podejść.
Dlaczego to takie istotne? Ponieważ metryka pass@k, szczególnie gdy używamy większych wartości k (np. pass@100 czy pass@256), nie mierzy jedynie przeciętnej skuteczności modelu, którą widzisz na co dzień. Zamiast tego, pozwala ona zajrzeć znacznie głębiej i oszacować rzeczywiste granice jego zdolności rozumowania. Pokazuje, czy dana umiejętność w ogóle istnieje w repertuarze modelu, nawet jeśli nie jest ona dla niego łatwo dostępna na zawołanie, przy pierwszej próbie. Dzięki takiemu podejściu możemy znacznie rzetelniej ocenić, czy trening RLVR faktycznie poszerza te fundamentalne granice możliwości modelu, czy może dzieje się z nimi coś zupełnie innego.
Zaskakujące Odkrycia - Czy RLVR spełnia oczekiwania?
Znasz już więc narzędzie - metrykę pass@k - które pozwala nam zajrzeć głębiej niż tylko na powierzchnię możliwości modelu. Uzbrojeni w tę wiedzę, badacze postanowili dokładnie przyjrzeć się, co tak naprawdę dzieje się z modelami językowymi po treningu RLVR. I tu, Drogi Czytelniku, zaczyna się najciekawsza część tej historii, bo wyniki okazały się co najmniej zaskakujące, a dla niektórych (dla mnie) być może nawet rewolucyjne w postrzeganiu tej technologii.
Badanie (z linkiem): Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Pierwsza obserwacja zdawała się potwierdzać początkowy entuzjazm. Modele trenowane metodą RLVR faktycznie stawały się lepsze, jeśli spojrzeć na ich wyniki przy małej liczbie prób - czyli na pass@1. Oznacza to, że po takim treningu model częściej podawał prawidłową odpowiedź już za pierwszym razem. Wyglądało to tak, jakby stał się pewniejszy siebie, bardziej naostrzony na szybkie i skuteczne rozwiązywanie problemów. Na pierwszy rzut oka sukces! Model wydaje się mądrzejszy, prawda?
Ale (i to jest duże "ale", które zmienia perspektywę), gdy badacze zaczęli zwiększać liczbę prób, czyli analizować pass@k dla większych wartości k (np. k=100, k=256), obraz zaczął się gwałtownie zmieniać. Okazało się bowiem, że modele bazowe - te same, które przed treningiem RLVR wydawały się słabsze przy pass@1, przy odpowiednio dużej liczbie prób zaczynały prześcigać swoich ulepszonych kolegów! Daj im wystarczająco dużo szans, a te "surowe", nietrenowane RLVR modele okazywały się zdolne do rozwiązania szerszego zakresu problemów. To tak, jakby miały szerszy, choć może mniej wyeksploatowany na co dzień i trudniej dostępny, horyzont wewnętrznych możliwości. Figura 2 w oryginalnym badaniu pięknie to ilustruje, pokazując krzywe pass@k dla różnych modeli, te bazowe często wspinają się wyżej przy dużym k.
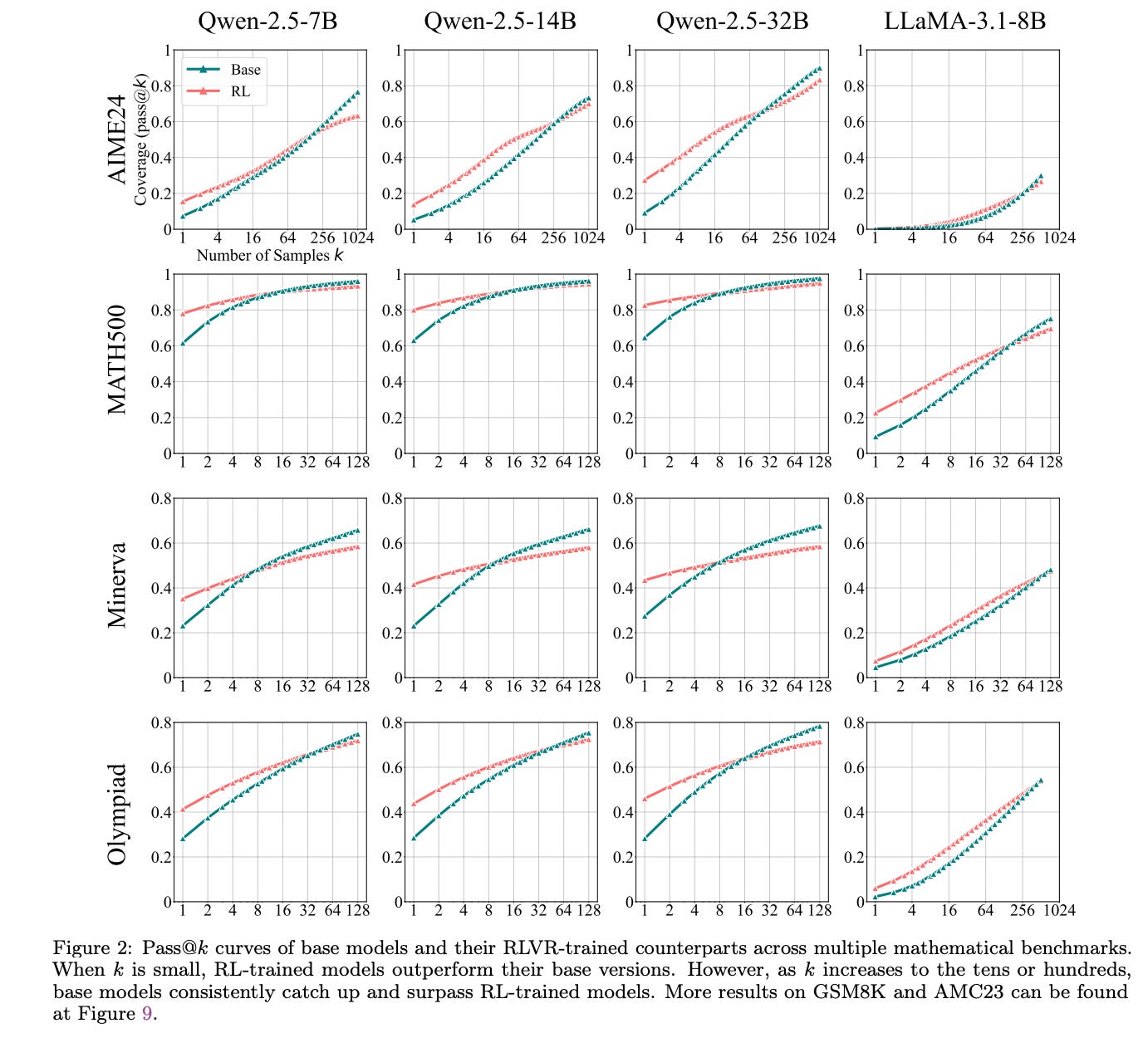
Co więcej, dalsza analiza pokazała coś jeszcze bardziej niepokojącego z punktu widzenia pierwotnych założeń. Spójrz na Figurę 1 z badania. Jej prawa część często pokazuje, że w miarę postępu treningu RLVR, średnia wydajność modelu (pass@1) rzeczywiście rośnie. Model staje się coraz lepszy w szybkim odpowiadaniu. Jednak jednocześnie pokrycie problemów, które model jest w stanie rozwiązać (reprezentowane przez pass@256), systematycznie maleje! Innymi słowy, trening RLVR, zamiast poszerzać, wydawał się zawężać ogólny zakres rozumowania modelu.
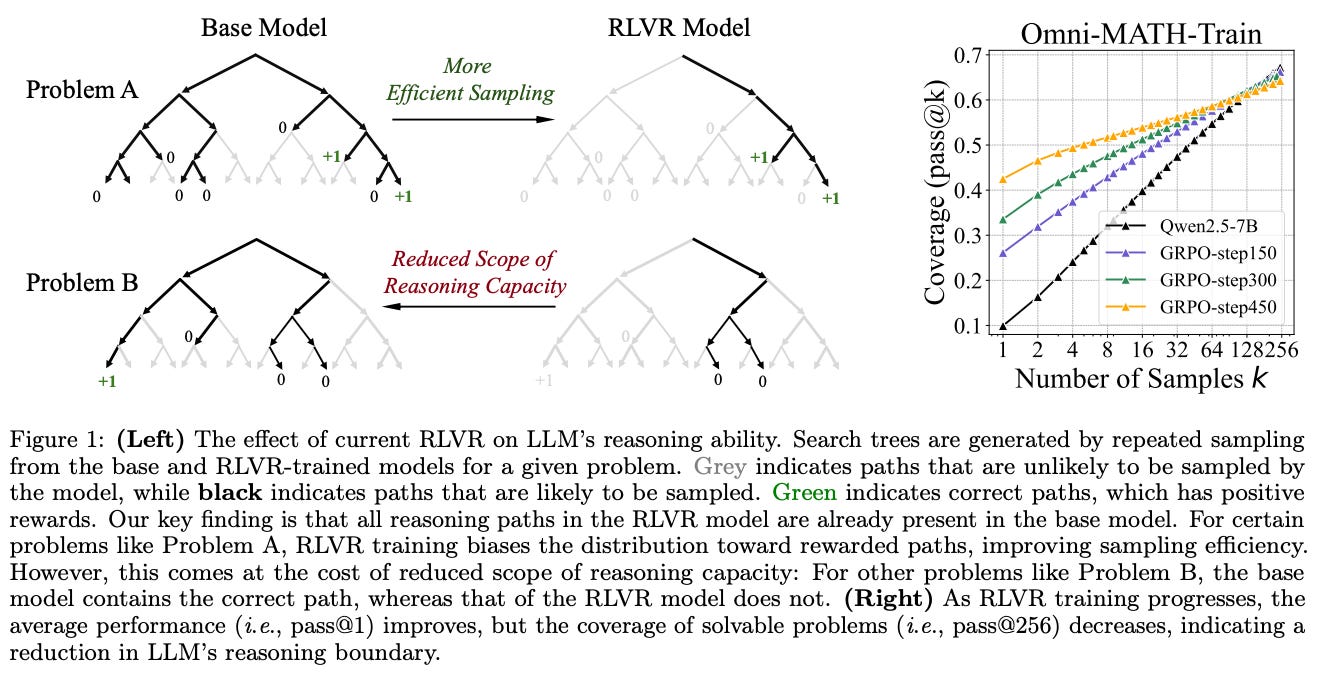
Wisienką na torcie tych zaskakujących odkryć jest obserwacja dotycząca samych ścieżek rozumowania. Lewa część Figury 1 sugeruje, że ścieżki rozumowania generowane przez modele RLVR wydają się już istnieć w modelach bazowych. Model po treningu RLVR nie tyle wymyśla nowe, genialne sposoby rozwiązania problemu, co raczej staje się znacznie sprawniejszy w odnajdywaniu i preferowaniu tych poprawnych ścieżek, które już wcześniej były w jego repertuarze, choć może rzadziej przez niego wybierane lub trudniej dostępne. RLVR działa więc bardziej jak precyzyjny i mocny reflektor, który oświetla i wzmacnia już istniejące, pożądane trasy w znanym sobie labiryncie. Nie tworzy nowych sposobów myślenia, a jedynie podkręca te, które model już znał.
Głębsze Spojrzenie - Dlaczego tak się dzieje?
Naturalnie rodzi się pytanie: dlaczego tak się dzieje? Co sprawia, że RLVR, zamiast otwierać nowe drzwi do rozumowania, zdaje się niektóre z nich wręcz przymykać? Spróbujmy więc zajrzeć za kulisy tego zjawiska, analizując poszlaki, które zebrali autorzy badania.
Pierwszym dowodem w naszej sprawie jest analiza dystrybucji dokładności modelu na poszczególnych zadaniach (w badaniu ilustruje to Figura 5).
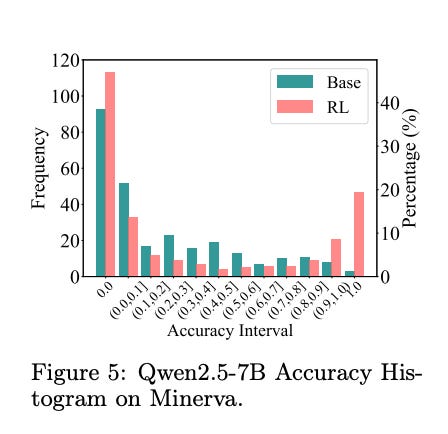
Histogram pokazuje jak często model osiąga dany poziom skuteczności, od kompletnego fiaska po stuprocentowy sukces. Okazuje się, że po treningu RLVR rośnie słupek przy bardzo wysokich dokładnościach, model staje się prawdziwym pewniakiem na niektórych zadaniach, rozwiązując je niemal za każdym razem. Ale, co niezwykle ciekawe, zauważalnie rośnie też słupek przy dokładności zerowej! Oznacza to, że pewna grupa problemów, które wcześniej model mógł z trudem, ale jednak czasami rozwiązać (może za piątą czy dziesiątą próbą), po treningu RLVR staje się dla niego kompletnie nierozwiązywalna. Zamiast więc poszerzać ogólne spektrum możliwości, model wydaje się specjalizować i optymalizować swoje działanie w pewnym obszarze, potencjalnie kosztem innych, trudniej dostępnych ścieżek.
Drugi istotny ślad to analiza pokrycia problemów (w badaniu możesz to zobaczyć w Tabelach 4 i 5, które zestawiają konkretne problemy).

Gdy badacze dokładnie porównali zbiory problemów, które potrafił rozwiązać model bazowy (dając mu wiele szans, zgodnie z metryką pass@k), z tymi, z którymi radził sobie model po treningu RLVR, odkryli, że problemy obsługiwane przez model RLVR stanowiły niemal idealny podzbiór problemów, z którymi już wcześniej potrafił sobie poradzić model bazowy. Innymi słowy, RLVR nie uczyło modelu rozwiązywania zupełnie nowych typów zadań, których wcześniej nie rozumiał. Raczej pomagało mu skupić się i stać się bardziej efektywnym na tych, które i tak były już w jego potencjalnym zasięgu.
Ostatnia, ale być może najbardziej sugestywna poszlaka, pochodzi z analizy tzw. perplexity (zobrazowanej na Figurze 6 w artykule).
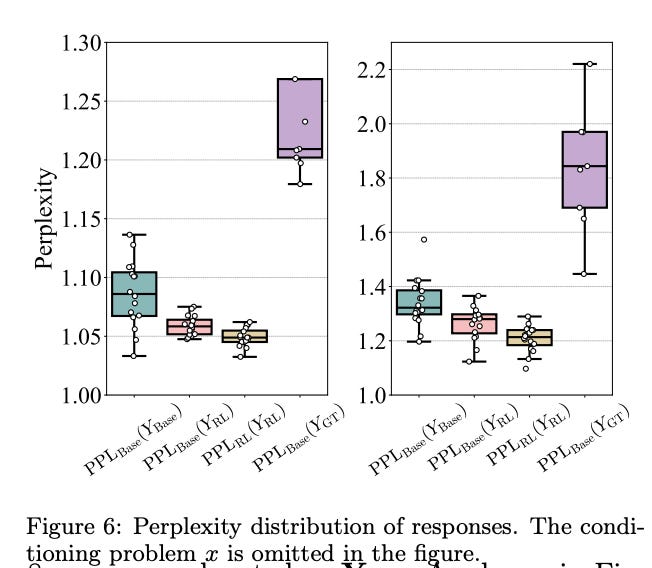
Perplexity to, w dużym uproszczeniu, miara tego, jak bardzo model jest zaskoczony daną sekwencją słów lub tokenów (czyli na przykład wygenerowaną odpowiedzią czy konkretną ścieżką rozumowania). Im niższa perplexity, tym bardziej naturalna, przewidywalna i w stylu danego modelu jest ta sekwencja.
Co więc odkryli badacze w kontekście RLVR? Otóż, gdy zmierzyli perplexity ścieżek rozumowania wygenerowanych przez model RLVR, ale oceniając je z perspektywy modelu bazowego (czyli tego sprzed treningu RLVR), okazało się, że ta perplexity jest niska! Oznacza to, że te nowe, efektywne ścieżki rozumowania z modelu RLVR wcale nie były takie nowe czy obce dla modelu bazowego. Brzmiały dla niego naturalnie, były w jego stylu. To bardzo mocna sugestia, że model bazowy już wcześniej znał te sposoby rozumowania, miał je w swojej dystrybucji możliwych odpowiedzi, nawet jeśli nie korzystał z nich tak często lub tak efektywnie, jak po wytrenowaniu przez RLVR.
Podsumowując nasze śledztwo: wszystkie te poszlaki - zmiany w dystrybucji dokładności, analiza pokrycia problemów i wyniki analizy perplexity - składają się na spójny obraz. Wskazują one z dużą dozą prawdopodobieństwa, że obecne metody RLVR nie tyle obdarowują modele fundamentalnie nowymi zdolnościami czy strategiami rozumowania, co raczej działają jak zaawansowany system optymalizacji: wyszukują i wzmacniają te strategie i ścieżki, które były już obecne w ich początkowej wiedzy i możliwościach.
A Może Inaczej? RLVR kontra Destylacja.
Skoro więc ten konkretny rodzaj treningu niekoniecznie prowadzi do odkrywania przez AI zupełnie nowych kontynentów rozumowania, to czy jest jakaś inna droga? Czy istnieje sposób, aby faktycznie poszerzyć horyzonty myślowe naszych cyfrowych asystentów, nauczyć je czegoś autentycznie nowego?
Okazuje się, że tak, a przynajmniej badanie, na którym się opieramy, wskazuje na jedną z takich obiecujących metod. Nazywa się ona destylacją (ang. distillation).
Na czym to polega? Wyobraź sobie, że zamiast kazać uczniowi samemu, metodą prób i błędów oraz sporadycznych nagród, dochodzić do wszystkich rozwiązań (co trochę przypomina działanie RLVR, gdzie model sam eksploruje przestrzeń możliwości), postanawiasz pokazać mu, jak myśli, rozumuje i pracuje prawdziwy, wybitny ekspert w danej dziedzinie. W świecie AI tym ekspertem jest zazwyczaj znacznie potężniejszy, bardziej zaawansowany model językowy (nazywany modelem-nauczycielem lub teacher model). Uczeń (czyli model, który chcemy ulepszyć, często mniejszy i mniej zasobożerny) nie dostaje tylko suchych przykładów zadań i ostatecznych odpowiedzi. Zamiast tego, ma wgląd w całe, często długie i złożone, ścieżki myślowe (chains of thought lub CoT) wygenerowane przez nauczyciela podczas rozwiązywania problemów. Uczy się naśladować nie tylko końcowy wynik, ale i sam proces dochodzenia do niego, niejako podpatrując strategie mistrza.
I tu dochodzimy do kluczowej różnicy w kontekście naszych dotychczasowych rozważań. Pamiętasz, jak mówiliśmy, że RLVR wydaje się być ograniczone wrodzonymi możliwościami modelu bazowego? Destylacja zdaje się mieć potencjał, by tę barierę przekroczyć. Ponieważ uczeń czerpie wiedzę i wzorce bezpośrednio od nauczyciela, który sam może posiadać szersze i bardziej zaawansowane zdolności rozumowania, istnieje realna szansa, że uczeń przejmie i zaadaptuje część tych nowych dla siebie wzorców i strategii.
Potwierdzają to wyniki przedstawione na Figurze 7 w analizowanym badaniu.
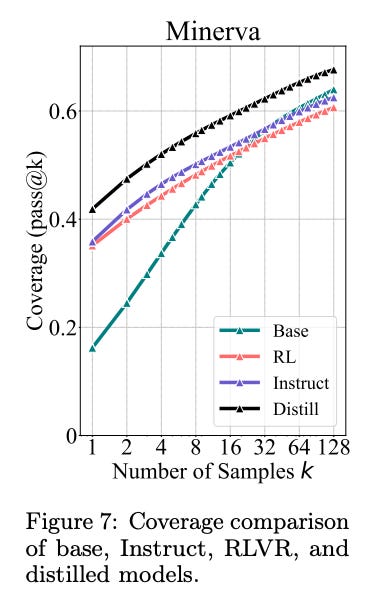
Gdy porównasz krzywą pass@k modelu bazowego z modelem, który przeszedł proces destylacji od silniejszego nauczyciela, zobaczysz coś wymownego. Krzywa modelu destylowanego konsekwentnie i znacząco przewyższa krzywą modelu bazowego na całej jej długości, nawet przy bardzo dużych wartościach k. Oznacza to, że model po destylacji jest w stanie rozwiązać więcej problemów, jego fundamentalne granice rozumowania faktycznie się poszerzyły. Nauczył się czegoś, czego model bazowy sam z siebie, nawet przy wielu próbach, nie był w stanie osiągnąć. To tak, jakby uczeń nie tylko nauczył się szybciej rozwiązywać znane zadania, ale posiadł zupełnie nowe techniki, których wcześniej nie znał.
Widzisz więc fundamentalną różnicę: podczas gdy obecne metody RLVR wydają się głównie optymalizować i lepiej wykorzystywać to, co już w modelu drzemie, destylacja otwiera drzwi do transferu zupełnie nowych kompetencji od bardziej zaawansowanego mentora.
Co z tego wynika dla Ciebie (i dla AI)?
Pamiętasz to fundamentalne pytanie, które unosiło się nad naszymi rozważaniami od samego początku: czy sztuczna inteligencja naprawdę uczy się myśleć na nowo, czy może tylko doskonali znane już sobie ścieżki? Wyniki, które analizowaliśmy, zdają się rzucać na to światło, które każe nam nieco zweryfikować nasze (a przynajmniej moje) wcześniejsze, być może zbyt optymistyczne, założenia. Wygląda na to, że obecne metody RLVR, choć czynią modele bardziej efektywnymi w pewnych aspektach, niekoniecznie obdarowują je zdolnością do fundamentalnie nowego, odkrywczego rozumowania.
Czy to oznacza, że marzenie o AI, która sama odkrywa nowe, nieznane horyzonty myślenia, jest tylko mrzonką? Niekoniecznie. I tu właśnie warto wsłuchać się w głos rozsądku i nadziei, który płynie od samych badaczy. Yang Yue, jeden ze współautorów omawianej pracy, podkreśla, że choć ich badanie wykazało, iż obecne metody RLVR nie zademonstrowały jeszcze zdolności wykraczających poza model bazowy, to nie ma to na celu dyskredytowania potencjału uczenia przez wzmacnianie (RL) jako takiego. Wręcz przeciwnie, Yue deklaruje się jako mocno wierzący w RL, które co do zasady może odblokować nowe zdolności, tak jak to widzieliśmy choćby w przypadku AlphaZero. Chodzi raczej o precyzyjną ocenę obecnego wpływu RLVR, abyśmy wiedzieli, gdzie stoimy.
Potencjał RL wciąż więc czeka na pełne wykorzystanie. Jak zauważają autorzy w swoim artykule, i co podkreśla Yue, są oni optymistami i z niecierpliwością oczekują postępów w kilku kluczowych obszarach, które mogą być niezbędne, by modele językowe faktycznie zaczęły myśleć poza schematami swoich modeli bazowych. Te kierunki to między innymi:
Dalsze skalowanie RL: Być może obecne eksperymenty są po prostu na zbyt małą skalę, by zaobserwować emergencję prawdziwie nowych zdolności.
Udoskonalone metody eksploracji: Modele muszą efektywniej przeszukiwać ogromną przestrzeń możliwych strategii. Tutaj wymienia się takie podejścia jak nagrody wewnętrzne (intrinsic rewards) czy zaawansowane techniki przeszukiwania drzew (np. MCTS).
Bardziej zróżnicowane i interaktywne środowiska treningowe: Potrzebne są bardziej złożone place zabaw dla AI (np. Reasoning Gym), które umożliwią wieloturowe interakcje i rozwój bardziej agencyjnych zachowań.
Lepsze mechanizmy przypisywania zasług (credit assignment): W długich łańcuchach rozumowania kluczowe jest, aby model wiedział, które kroki były naprawdę wartościowe.
Co to wszystko oznacza dla Ciebie, jako obserwatora i użytkownika AI? Przede wszystkim to, że droga do prawdziwie myślącej AI jest prawdopodobnie bardziej złożona i pełna niuansów, niż mogłoby się wydawać na pierwszy rzut oka. Nie ma tu prostych recept i magicznych rozwiązań. Jednak każde takie badanie, nawet jeśli studzi nieco entuzjazm, jest niezwykle cenne. Pokazuje nam realne ograniczenia, zmusza do krytycznego myślenia i, co najważniejsze, wskazuje kierunki, w których warto podążać, by te ograniczenia przezwyciężyć.

Przed 2. tygodniami w tej sekcji znaleźć można było listę darmowych kursów na dobry początek romansu z AI - o! w tym mailu:
✨ Najlepsze wydarzenie od Google jakie kiedykolwiek miało miejsce

🔉Wolisz wersję audio? Nie możesz przeczytać teraz maila?
Jednak co jeśli nie trzeba przekonywać Cię do tego, że adopcja AI w Twojej firmie to oczywistość? Prowadzisz biznes…
…i potrzebna Ci nie tyle wiedza o AI jako takiej, tylko konkret na temat tego jak ją wdrożyć w firmie. Co wtedy?
Sięgasz po ten kurs i narzędzia Franciszka:

I tak jak generalnie sądzę, że wiele można samemu, zdaje sobie też sprawę, że nie wszyscy mają czas i pomysł na samodzielną naukę. Ponadto dobrze uporządkowana wiedza, podana w ciekawy sposób, usystematyzowana, dająca narzędzia i nie rozproszona na ogół, a dedykowana dla roli zawodowej, branży lub sektora, może pomóc wzrosnąć szybciej. Bo kurs jednak zmusza do intensywnej pracy i może być mobilizujący jak trener personalny na siłowni. Niech więc będzie, że Georgiew to taki coach 💪🏻🧠
Pominę całość programu oferowanego w tym kursie, bo już o nim wspominaliśmy w AI kursy (🔗 zajrzyj do całości), ale skupie się na punkcie 5. oraz 7. z jego agendy:
Leadership: zarządzanie bez chaosu
AI Journaling i wsparcie dla liderów (o potrzebie budowania liderów AI w firmach pisałem w poprzednich wydaniach newslettera, to mega ważne)
Mapowanie i optymalizacja procesów
Onboarding i rozwój zespołu
Wdrożenie AI w organizacji
Podsumowanie i wizja przyszłości
Framework implementacji AI w MŚP
Następne kroki z AION i AI community
To dwa konkrety dla firm i szczególnie na AI Journaling oraz na AION miałbym na miejscu właściciela biznesu apetyt 🤤
Franciszek nazywa to połączenie superinteligentnym asystentem - psychologiem, coachem, strategiem biznesowym i narzędziem w jednym. Jak pisze o tym autor kursu: “magia nie tkwi w samym AI, ale połączeniu najlepszych modeli AI ze spersonalizowanym kontekstem, który zbudujesz w swoim dzienniku”. Franciszek pokaże Ci jak prowadzić Journaling z AION-em - zaawansowanym narzędziem, które nie jest tylko aplikacją, ale całym ekosystemem zaprojektowany, by wspierać biznesy i liderów AI.

AION działa zarówno w środowisku firmowym, jak i indywidualnym. To narzędzia, które wspierają codzienną organizację, rozwój osobisty, koncentrację i zarządzanie czasem - bez względu na to, czy prowadzisz firmę, uczysz się, pracujesz zdalnie czy po prostu chcesz lepiej wykorzystać swój dzień.
Ale AION to przede wszystkim narzędzie biznesowe i odpowiada ono na potrzebę poufności i analizy danych w organizacji.
To właśnie do tych dwóch elementów - AI Journalingu i AION - uzyskasz dostęp, zapisując się do kurs Laba z Franciszkiem.
Ale bardzo interesujący wydaje mi się również ten punkt programu kursu: Onboarding i rozwój zespołu.
Onboarding zespołu bowiem jest fundamentalny dla skutecznego wdrożenia AI w firmie. Bez odpowiedniego przygotowania pracowników, nawet najlepszy lider - Ty, ani najlepsze narzędzia, nie przyniosą oczekiwanych rezultatów.
Budowanie akceptacji dla AI: Pracownicy często obawiają się, że AI zastąpi ich pracę. Dobry onboarding rozwiewa te obawy, pokazując, jak AI wspiera, a nie konkuruje, oraz buduje zaufanie do technologii.
Szybkie przystosowanie do narzędzi: Wdrożenie AI wymaga nauki obsługi nowych systemów. Skuteczny onboarding zapewnia, że zespół rozumie, jak używać narzędzi w codziennej pracy, co przyspiesza adopcję.
Dopasowanie do procesów firmy: Onboarding pozwala zintegrować AI z istniejącymi procesami, np. mapowaniem i optymalizacją, o czym mowa w kursie. Pracownicy uczą się, jak AI może usprawnić ich zadania.
Rozwój kompetencji: Używanie AI narzędzi wymaga nowych umiejętności, np. analizy danych czy strategicznego myślenia ze wsparciem AI. Onboarding wspiera rozwój tych kompetencji, tworząc liderów AI w firmie.
Kultura innowacji: Dobrze przeprowadzony onboarding buduje otwartą postawę wobec innowacji, co jest kluczowe dla długoterminowego sukcesu wdrożenia AI.
W skrócie. AI więc to nie tylko nauka obsługi narzędzi, ale inwestycja w kulturę firmy i przygotowanie zespołu do współpracy z AI. Jeśli więc prowadzisz biznes, zainteresuj się kursami takimi i jak ten od 🔗 Laba i Franciszka


🥡 AI na Wynos - nowości AI
👑 Polska “AI Gra o Tron” - oglądaj
😱 Grozi nam krach na rynku pracy. Ale nie to jest najgorsze… - czytaj
🇵🇱 Nowa Polityka AI - "możesz dołączyć do konsultacji i pomóc współtworzyć polską AI” - czytaj
🌐 Nowa strona internetowa rządowego portalu sztucznej inteligencji - zobacz
🇩🇪 Sztuczna inteligencja na niemieckim rynku pracy - czytaj
🎓 Podsumowanie 5. miesięcy nauki w prywatnej szkole w Teksasie, gdzie nauka oparta jest wyłącznie z wykorzystaniem AI - czytaj nitkę
🥩 Co ma wspólnego sztuczna inteligencja z mięsem? - czytaj
🔬 Jak sztuczna inteligencja wpływa na świat badań i rozwoju - czytaj
♉️ AI vs. rak prostaty - czytaj
⚽️ Sztuczna inteligencja znów wchodzi na boiska. Będzie wykrywać spalonego -czytaj
🏦 Sztuczna inteligencja w bankach. Klienci wciąż wolą obsługę człowieka - czytaj
🔍💸 Wszyscy użytkownicy Perplexity mają dostęp do danych SEC - dostęp do kompleksowych danych finansowych - zobacz
🔞 Wygenerowali pornografię AI, wykorzystując wizerunek koleżanki. Policja zbada sprawę - czytaj
🦮 Sztuczna inteligencja i ochrona zwierząt: sojusznik czy zagrożenie? - czytaj
🦾 Bioniczne ramię - zobacz
📖 Sztuczna inteligencja rozwikłała sekrety Biblii - czytaj
📕 Książka napisana za pomocą sztucznej inteligencji - czytaj/wideo
📬 Czytałeś/-aś ostatnie wydanie ze środy? Szukaj w skrzynce maila pt. tytułem:
“👨🏻🎓🤖 Gdzie studiować AI w Polsce? 🎓✨ Kurs AI dla Twojego biznesu, w którym powinieneś chcieć wciąć udział 💼 Oferty pracy AI”

Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model? arXiv:2504.13837 [cs.AI]
Zdaje się, że nie polecaliśmy Ci tego video, a jest konkretne. Andrej Karpathy, były pracownik Tesli i OpenAI przedstawia jak on korzysta z dużych modeli językowych. Warto to obejrzeć, Andrej, który już często się pojawiał w tej sekcji to świetny nauczyciel i badacz.
Dzięki za przeczytanie tego wydania newslettera Horyzont AI!
- @MarcinUszyński @JakubNorkiewicz
Jeśli jesteś tu pierwszy raz - dołącz za darmo, aby regularnie otrzymywać takie treści na swojego maila.
A jeśli już jesteś subskrybentem i dotarłeś tutaj, oceń treść:
Jeżeli chcesz słuchać treści newsletterów w formie audio, to subskrybuj nasz kanał youtube - gorąco zachęcamy!

